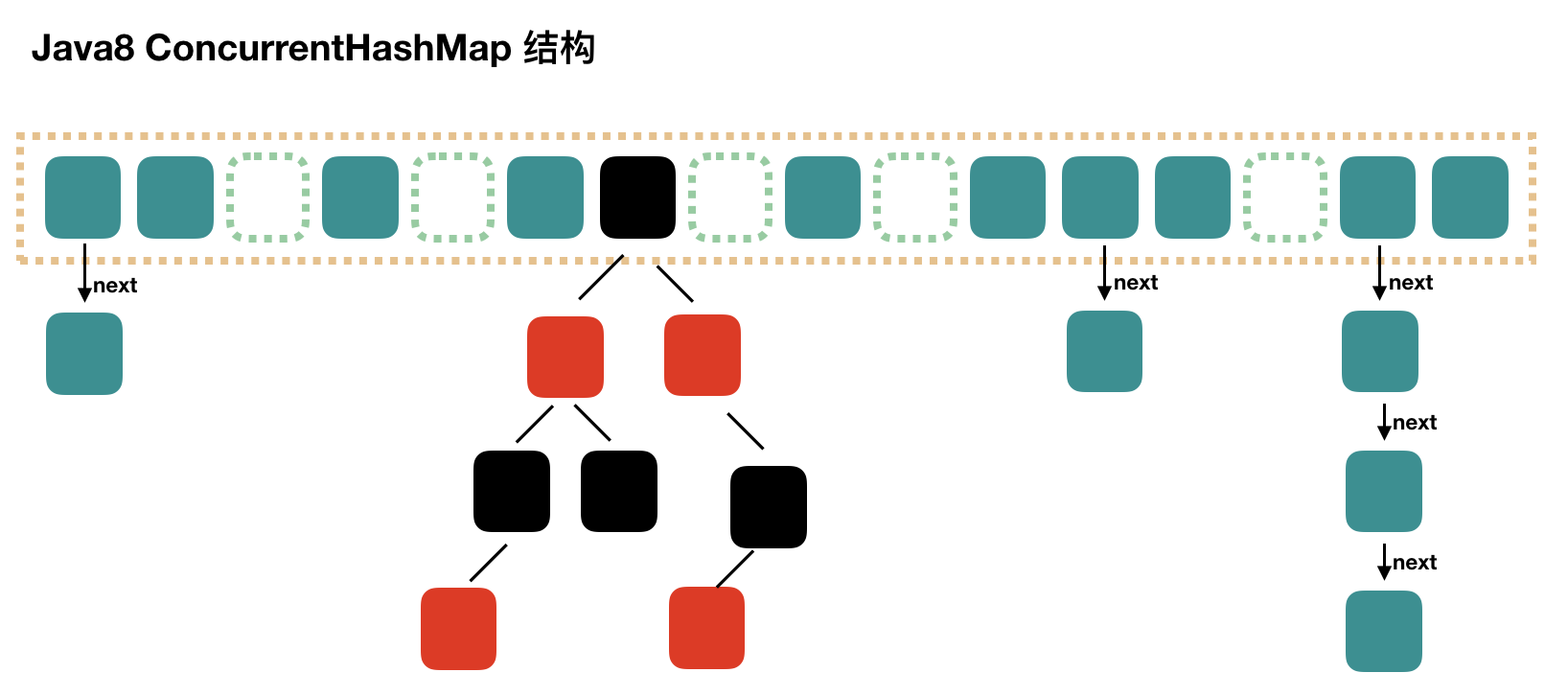
一、Hash map 的一些简单介绍
真难啊,记录一个这个过程,最难的在于扩容,数据迁移操作不容易看懂。
1 | // 这构造函数里,什么都不干 |
然后是 put的全过程
1 |
|
put 的主流程看完了,但是至少留下了几个问题,第一个是初始化,第二个是扩容,第三个是帮助数据迁移,这些我们都会在后面进行一一介绍。
初始化数组:initTable
这个比较简单,主要就是初始化一个合适大小的数组,然后会设置 sizeCtl。
初始化方法中的并发问题是通过对 sizeCtl 进行一个 CAS 操作来控制的。
初始化的问题
先是初始化的问题:initTable
这个比较简单,主要就是初始化一个合适大小的数组,然后会设置 sizeCtl。
初始化方法中的并发问题是通过对 sizeCtl 进行一个 CAS 操作来控制的。
1 | private final Node<K,V>[] initTable() { |
链表转红黑树: treeifyBin
前面我们在 put 源码分析也说过,treeifyBin 不一定就会进行红黑树转换,也可能是仅仅做数组扩容。我们还是进行源码分析吧。
1 | private final void treeifyBin(Node<K,V>[] tab, int index) { |
扩容:tryPresize
如果说 Java8 ConcurrentHashMap 的源码不简单,那么说的就是扩容操作和迁移操作。
这个方法要完完全全看懂还需要看之后的 transfer 方法,读者应该提前知道这点。
这里的扩容也是做翻倍扩容的,扩容后数组容量为原来的 2 倍。
1 | // 首先要说明的是,方法参数 size 传进来的时候就已经翻了倍了 |
这个方法的核心在于 sizeCtl 值的操作,首先将其设置为一个负数,然后执行 transfer(tab, null),再下一个循环将 sizeCtl 加 1,并执行 transfer(tab, nt),之后可能是继续 sizeCtl 加 1,并执行 transfer(tab, nt)。
所以,可能的操作就是执行 1 次 transfer(tab, null) + 多次 transfer(tab, nt),这里怎么结束循环的需要看完 transfer 源码才清楚。
数据迁移:transfer
下面这个方法很点长,将原来的 tab 数组的元素迁移到新的 nextTab 数组中。
虽然我们之前说的 tryPresize 方法中多次调用 transfer 不涉及多线程,但是这个 transfer 方法可以在其他地方被调用,典型地,我们之前在说 put 方法的时候就说过了,请往上看 put 方法,是不是有个地方调用了 helpTransfer 方法,helpTransfer 方法会调用 transfer 方法的。
此方法支持多线程执行,外围调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab 参数为 null,之后再调用此方法的时候,nextTab 不会为 null。
阅读源码之前,先要理解并发操作的机制。原数组长度为 n,所以我们有 n 个迁移任务,让每个线程每次负责一个小任务是最简单的,每做完一个任务再检测是否有其他没做完的任务,帮助迁移就可以了,而 Doug Lea 使用了一个 stride,简单理解就是步长,每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务。所以,我们就需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。当然,这里说的第二个线程不是真的一定指代了第二个线程,也可以是同一个线程,这个读者应该能理解吧。其实就是将一个大的迁移任务分为了一个个任务包。
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |