gc效果优化如图:
原理以及调优过程:
一、young gc的耗时统计二、常见垃圾回收器GC日志参数基本策略三、优化步骤优化四、现状确定目标优化
一、young gc的耗时统计
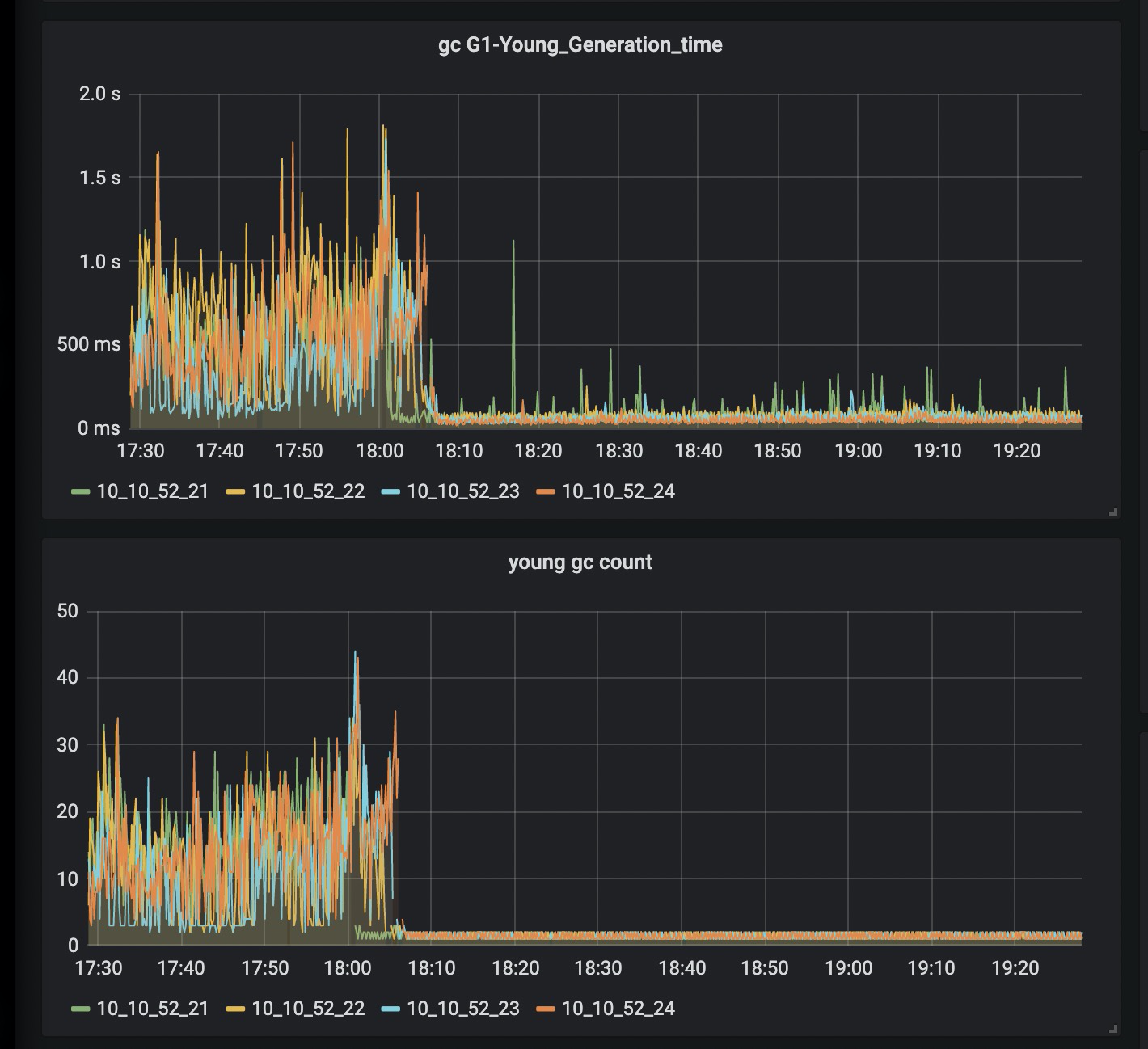
- 目前的young gc耗时以及次数如下:


- young gc的耗时较长,吞吐量较低。核心是解决耗时的问题。YoungGC 的耗时在 200ms 以上,几乎没有什么对象晋升,频率 4-5 秒一次。GC 日志截图如下。

- gc的配置如下:
二、常见垃圾回收器
不同的垃圾回收器,适用于不同的场景。常用的垃圾回收器:
- 串行(Serial)回收器是单线程的一个回收器,简单、易实现、效率高。
- 并行(ParNew)回收器是Serial的多线程版,可以充分的利用CPU资源,减少回收的时间。
- 吞吐量优先(Parallel Scavenge)回收器,侧重于吞吐量的控制。
- 并发标记清除(CMS,Concurrent Mark Sweep)回收器是一种以获取最短回收停顿时间为目标的回收器,该回收器是基于“标记-清除”算法实现的。
GC日志
每一种回收器的日志格式都是由其自身的实现决定的,换而言之,每种回收器的日志格式都可以不一样。但虚拟机设计者为了方便用户阅读,将各个回收器的日志都维持一定的共性。
参数基本策略
各分区的大小对GC的性能影响很大。如何将各分区调整到合适的大小,分析活跃数据的大小是很好的切入点。
活跃数据的大小是指,应用程序稳定运行时长期存活对象在堆中占用的空间大小,也就是Full GC后堆中老年代占用空间的大小。可以通过GC日志中Full GC之后老年代数据大小得出,比较准确的方法是在程序稳定后,多次获取GC数据,通过取平均值的方式计算活跃数据的大小。活跃数据和各分区之间的比例关系如下:
| 空间 | 倍数 |
|---|---|
| 总大小 | 3-4 倍活跃数据的大小 |
| 新生代 | 1-1.5 活跃数据的大小 |
| 老年代 | 2-3 倍活跃数据的大小 |
| 永久代 | 1.2-1.5 倍Full GC后的永久代空间占用 |
例如,根据GC日志获得老年代的活跃数据大小为300M,那么各分区大小可以设为:
总堆:1200MB = 300MB × 4* 新生代:450MB = 300MB × 1.5* 老年代: 750MB = 1200MB - 450MB*
这部分设置仅仅是堆大小的初始值,后面的优化中,可能会调整这些值,具体情况取决于应用程序的特性和需求。

三、优化步骤
GC优化一般步骤可以概括为:确定目标、优化参数、验收结果。
举例:假设单位时间T内发生一次持续25ms的GC,接口平均响应时间为50ms,且请求均匀到达,根据下图所示:

那么有(50ms+25ms)/T比例的请求会受GC影响,其中GC前的50ms内到达的请求都会增加25ms,GC期间的25ms内到达的请求,会增加0-25ms不等,如果时间T内发生N次GC,受GC影响请求占比=(接口响应时间+GC时间)×N/T 。可见无论降低单次GC时间还是降低GC次数N都可以有效减少GC对响应时间的影响。
优化
通过收集GC信息,结合系统需求,确定优化方案,例如选用合适的GC回收器、重新设置内存比例、调整JVM参数等。
进行调整后,将不同的优化方案分别应用到多台机器上,然后比较这些机器上GC的性能差异,有针对性的做出选择,再通过不断的试验和观察,找到最合适的参数。
四、现状
确定目标
服务情况:young gc 每分钟25次,每次大概200ms。接口响应时间大概平均为400ms 。(200ms+400ms)× 25次/60000ms = 25% 请求时间会增加。
优化目标:降低P99时间。
优化
首先优化Minor GC频繁问题。通常情况下,由于新生代空间较小,Eden区很快被填满,就会导致频繁Minor GC,因此可以通过增大新生代空间来降低Minor GC的频率。例如在相同的内存分配率的前提下,新生代中的Eden区增加一倍,Minor GC的次数就会减少一半。
这时很多人有这样的疑问,扩容Eden区虽然可以减少Minor GC的次数,但会增加单次Minor GC时间么?根据上面公式,如果单次Minor GC时间也增加,很难保证最后的优化效果。我们结合下面情况来分析,单次Minor GC时间主要受哪些因素影响?是否和新生代大小存在线性关系? 首先,单次Minor GC时间由以下两部分组成:T1(扫描新生代)和 T2(复制存活对象到Survivor区)如下图。(注:这里为了简化问题,我们认为T1只扫描新生代判断对象是否存活的时间,其实该阶段还需要扫描部分老年代,后面案例中有详细描述。)

- 扩容前:新生代容量为R ,假设对象A的存活时间为750ms,Minor GC间隔500ms,那么本次Minor GC时间= T1(扫描新生代R)+T2(复制对象A到S)。
- 扩容后:新生代容量为2R ,对象A的生命周期为750ms,那么Minor GC间隔增加为1000ms,此时Minor GC对象A已不再存活,不需要把它复制到Survivor区,那么本次GC时间 = 2 × T1(扫描新生代R),没有T2复制时间。
可见,扩容后,Minor GC时增加了T1(扫描时间),但省去T2(复制对象)的时间,更重要的是对于虚拟机来说,复制对象的成本要远高于扫描成本,所以,单次Minor GC时间更多取决于GC后存活对象的数量,而非Eden区的大小。因此如果堆中短期对象很多,那么扩容新生代,单次Minor GC时间不会显著增加。下面需要确认下服务中对象的生命周期分布情况:

这是典型G1的Evacuation Pause(转移暂停),在这个阶段存活的对象被从一个分区(年轻代或年轻代+老年代)拷贝到另一个分区。
这是一个STW,所有的应用线程停止在安全点。

1 | 0.522: [GC pause (young), 0.15877971 secs] |
这是一个转移暂停,距离进程启动的0.522秒开始,所有被转移的是年轻代分区,一共花费了0.15877971秒。
转移暂停也可以是混合的,比如:1.730:[GC pause (mixed), 0.32714353 secs],此时分区包含所有的年轻代分区和部分老年代分区。
1 | [Parallel Time: 157.1 ms] |
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
0.0 106496.0 0.0 106496.0 2043904.0 1048576.0 6238208.0 2202526.5 188880.0 176103.4 23036.0 20985.0 32734 1590.882 0 0.000 1590.882

当前参数如下:可以看出:
MC设计不合理:元数据空间十倍于使用大小
OC 老年
http://zhongmingmao.me/2019/01/08/jvm-advanced-command/ S0C 永远为0
S0C和S0U始终为0,这是因为使用G1 GC时,JVM不再设置Eden区、Survivor区和Old区的内存边界,而是将堆划分为若干个等长内存区域
每个内存区域都可以作为Eden区、Survivor区和Old区,并且可以在不同区域类型之间来回切换
因此,逻辑上只有一个Survivor区,当需要迁移Survivor区中的数据(Copying),只需要申请一个或多个内存区域,作为新的Survivor区
当发生垃圾回收时,JVM可能出现Survivor内存区域内的对象
全被回收
或者
全被晋升
的现象
- 此时,JVM会将这块内存区域回收,并标记为可分配
- 结果堆中可能完全没有Survivor内存区域,S1C和S1U均为0


1 | `回收器的选择:https:``//blog``.csdn.net``/lxlmycsdnfree/article/details/81531363` `CMS回收器的好处``-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly` |
JDK 8开始把类的元数据放到本地化的堆内存(native heap)中,这一块区域就叫Metaspace,中文名叫元空间。
使用本地化的内存有什么好处呢?最直接的表现就是java.lang.OutOfMemoryError: PermGen 空间问题将不复存在,因为默认的类的元数据分配只受本地内存大小的限制,也就是说本地内存剩余多少,理论上Metaspace就可以有多大(貌似容量还与操作系统的虚拟内存有关?这里不太清楚),这解决了空间不足的问题。不过,让Metaspace变得无限大显然是不现实的,因此也要限制Metaspace的大小:
使用-XX:MaxMetaspaceSize参数来指定Metaspace区域的大小。
JVM默认在运行时根据需要动态地设置MaxMetaspaceSize的大小
关于元空间的一些误区:https://www.jianshu.com/p/b448c21d2e71。不是说配置了-XX:MetaspaceSize=50m -XX:MaxMetaspaceSize=256m 这个参数他的设置就会使你的metaspace区使用量达到这个值。